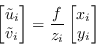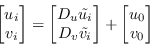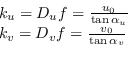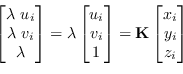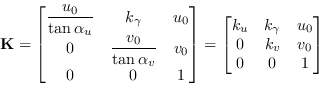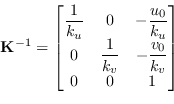Next: Distorsione della lente Up: Elementi di analisi per Previous: Lucas-Kanade
In questo capitolo viene affrontato il problema di descrivere il processo attraverso il quale la luce incidente sugli oggetti viene impressa su un sensore digitale. Tale concetto è fondamentale nell'elaborazione delle immagini in quando fornisce la relazione che lega i punti di un'immagine con la loro posizione nel mondo, ovvero permette di determinare la zona del mondo associata a un pixel dell'immagine o, viceversa, individuare l'area dell'immagine che raccoglie una determinata regione in coordinate mondo.
Il modello proiettivo universalmente accettato, detto della Pin-Hole Camera, è basato su semplici rapporti geometrici.
In figura 8.1 è mostrato uno schema molto semplificato di come avviene la formazione dell'immagine sul sensore.
Il punto osservato
![]() , espresso in coordinate camera, viene proiettato su una cella del sensore
, espresso in coordinate camera, viene proiettato su una cella del sensore
![]() .
Tutti questi raggi passano per uno stesso punto: il punto focale (pin-hole).
.
Tutti questi raggi passano per uno stesso punto: il punto focale (pin-hole).
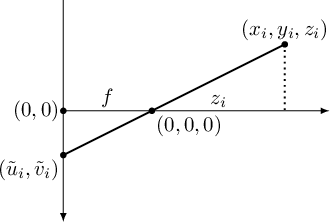 |
Analizzando la figura 8.1 si vede come i rapporti tra triangoli simili generati dai raggi ottici descrivono l'equazione che permette di proiettare un generico punto
![]() , espresso in coordinate camera (uno dei sistemi di riferimento in cui si può operare), in coordinate sensore
, espresso in coordinate camera (uno dei sistemi di riferimento in cui si può operare), in coordinate sensore
![]() :
:
Le coordinate sensore
![]() non sono le coordinate immagine ma sono ancora delle coordinate “intermedie”.
È quindi necessario applicare una ulteriore trasformazione per ottenere le coordinate immagine:
non sono le coordinate immagine ma sono ancora delle coordinate “intermedie”.
È quindi necessario applicare una ulteriore trasformazione per ottenere le coordinate immagine:
![]() e
e ![]() sono fattori di conversione tra le unità del sistema di riferimento del sensore (metri) con quelle immagine (pixel) e tengono conto dei diversi fattori di conversione coinvolti.
Con l'avvento dei sensori digitali normalmente
sono fattori di conversione tra le unità del sistema di riferimento del sensore (metri) con quelle immagine (pixel) e tengono conto dei diversi fattori di conversione coinvolti.
Con l'avvento dei sensori digitali normalmente ![]() .
.
In mancanza di informazioni, reperibili dai vari datasheet, su ![]() ,
, ![]() e
e ![]() , c'è la tendenza ad accorpare queste variabili in due nuove variabili chiamate
, c'è la tendenza ad accorpare queste variabili in due nuove variabili chiamate ![]() e
e ![]() , le lunghezze focali efficaci misurate in pixel, ottenibili in maniera empirica dalle immagini, come si vedrà nella sezione sulla calibrazione.
Queste variabili, coinvolte nella conversione tra coordinate sensore e coordinate immagine, sono tra loro in relazione come
, le lunghezze focali efficaci misurate in pixel, ottenibili in maniera empirica dalle immagini, come si vedrà nella sezione sulla calibrazione.
Queste variabili, coinvolte nella conversione tra coordinate sensore e coordinate immagine, sono tra loro in relazione come
A causa della presenza del rapporto, l'equazione (8.1) non è chiaramente rappresentabile in un sistema lineare.
Tuttavia risulta possibile modificare tale scrittura, aggiungendo un incognita ![]() e un vincolo ulteriore, per poter rappresentare in forma di sistema lineare tale equazione.
Per fare questo verrà sfruttata la teoria presentata in sezione 1.4 riguardante le coordinate omogenee.
Grazie alle coordinate omogenee si mostra facilmente che il sistema (8.1) si può scrivere come
e un vincolo ulteriore, per poter rappresentare in forma di sistema lineare tale equazione.
Per fare questo verrà sfruttata la teoria presentata in sezione 1.4 riguardante le coordinate omogenee.
Grazie alle coordinate omogenee si mostra facilmente che il sistema (8.1) si può scrivere come
La matrice ![]() , unendo le trasformazioni (8.2) e (8.3), può essere scritta come:
, unendo le trasformazioni (8.2) e (8.3), può essere scritta come:
Tale matrice non dipendendo, come vedremo successivamente, da fattori che non siano altri che quelli della camera stessa, è detta matrice dei fattori intrinseci.
La matrice ![]() è una matrice triangolare superiore, definita da 5 parametri.
è una matrice triangolare superiore, definita da 5 parametri.
Con i sensori digitali moderni e la costruzione di telecamere non manualmente ma con macchine a controllo numerico precise, è possibile porre lo skew factor ![]() , un fattore che tiene conto del fatto che l'angolo tra gli assi nel sensore non sia esattamente 90 gradi, a zero.
, un fattore che tiene conto del fatto che l'angolo tra gli assi nel sensore non sia esattamente 90 gradi, a zero.
Ponendo ![]() , l'inversa della matrice (8.5) si può scrivere come:
, l'inversa della matrice (8.5) si può scrivere come:
La conoscenza di questi parametri (vedi sezione 8.5 riguardante la calibrazione) determina la possibilità di trasformare un punto da coordinate camera a coordinate immagine o, viceversa, generare la retta in coordinate camera sottesa a un punto immagine.
Con questa modellazione, in ogni caso, non si è tenuto conto dei contributi dovuti alla distorsione della lente. Il modello della pin-hole camera è infatti valido solamente se le coordinate immagine che si utilizzano si riferiscono a immagini senza distorsione.