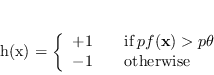Next: Alberi di Decisione Up: Classificazione Previous: Classificazione multiclasse
Il concetto di addestramento Ensemble richiama l'utilizzo di diversi classificatori, differenti, uniti in un certo modo per riuscire a massimizzare le prestazioni usando i punti di forza di ognuno e limitando le debolezze dei singoli.
Alla base del concetto di Ensemble Learning ci sono i classificatori deboli (weak classifier): un classificatore debole riesce a classificare almeno il ![]() dei campioni di un problema binario.
Sommati in un certo modo tra di loro, i classificatori deboli permettono di costruire un classificatore forte, risolvendo allo stesso tempo problemi tipici dei classificatori tradizionali (overfitting in primis).
dei campioni di un problema binario.
Sommati in un certo modo tra di loro, i classificatori deboli permettono di costruire un classificatore forte, risolvendo allo stesso tempo problemi tipici dei classificatori tradizionali (overfitting in primis).
L'origine dell'Ensemble Learning, del concetto di classificatore debole e in particolare il concetto di probably approximately correct learning (PAC) sono stati per primi introdotti da Valiant (Val84).
Di fatto le tecniche di Ensemble Learning non forniscono classificatori general purpose, ma indicano solo il modo ottimo per unire più classificatori tra loro.
Esempi di tecniche di Ensemble Learning sono
Esempi di classificatori deboli ampiamente usati in letteratura sono i Decision Stump (AL92) associati alle feature di Haar (sezione 6.1).
Il Decision Stump è un classificatore binario nella forma