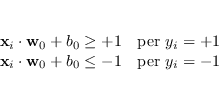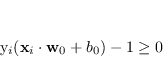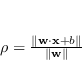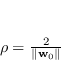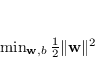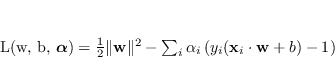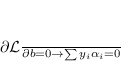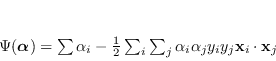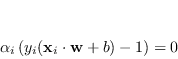Next: Soft Margin SVM Up: Classificazione Previous: LDA
LDA si pone come obiettivo quello di massimizzare la distanza statistica tra le classi ma non cerca di valutare quale sia l'effettivo margine di separazione tra di loro.
 |
SVM (CV95), come LDA, permette di ottenere un classificatore lineare basato su una funzione discriminante nella stessa forma mostrata in equazione (4.5).
SVM però va oltre: l'iperpiano ottimo in
![]() viene generato in maniera tale da separare “fisicamente” (decision boundary) gli elementi del problema di classificazione binario ovvero si pone come obiettivo quello di massimizzare il margine di separazione tra le classi.
Questo ragionamento premia molto per quanto riguarda la generalizzazione del classificatore.
viene generato in maniera tale da separare “fisicamente” (decision boundary) gli elementi del problema di classificazione binario ovvero si pone come obiettivo quello di massimizzare il margine di separazione tra le classi.
Questo ragionamento premia molto per quanto riguarda la generalizzazione del classificatore.
Siano pertanto definite come classi di classificazione quelle tipiche di un problema binario nella forma
![]() e si faccia riferimento all'iperpiano di formula (4.4).
Supponiamo che esistano dei parametri
e si faccia riferimento all'iperpiano di formula (4.4).
Supponiamo che esistano dei parametri
![]() ottimi tali che soddisfino il vincolo
ottimi tali che soddisfino il vincolo
Si può supporre che esistano, per ognuna delle categorie, uno o più vettori ![]() dove le disuguaglianze (4.17) diventano uguaglianze.
Tali elementi, chiamati Support Vectors, sono i punti più estremi della distribuzione e la loro distanza rappresenta la misura del margine di separazione tra le due categorie.
dove le disuguaglianze (4.17) diventano uguaglianze.
Tali elementi, chiamati Support Vectors, sono i punti più estremi della distribuzione e la loro distanza rappresenta la misura del margine di separazione tra le due categorie.
La distanza ![]() punto-piano (cfr. eq.(1.52)) vale
punto-piano (cfr. eq.(1.52)) vale
Per massimizzare il margine ![]() dell'equazione (4.19) bisogna minimizzare la sua inversa, ovvero
dell'equazione (4.19) bisogna minimizzare la sua inversa, ovvero
Questa classe di problemi (minimizzazione con vincoli come disuguaglianze o primal optimization problem) si risolvono utilizzando l'approccio di Karush-Kuhn-Tucker che è il metodo dei moltiplicatori di Lagrange generalizzato a disuguaglianze.
Attraverso le condizioni KKT si ottiene la funzione lagrangiana:
Su questa relazione sono valide le condizioni KKT tra le quali è di notevole importanza il vincolo, detto di Complementary slackness,
Risolvendo il problema quadratico (4.24), sotto il vincolo (4.22) e
![]() , i pesi che presentano
, i pesi che presentano
![]() saranno i Support Vectors.
Tali pesi, inseriti nelle equazioni (4.23) e (4.25), porteranno a ricavare l'iperpiano di massimo margine.
saranno i Support Vectors.
Tali pesi, inseriti nelle equazioni (4.23) e (4.25), porteranno a ricavare l'iperpiano di massimo margine.
Il metodo più usato per risolvere questo problema QP è il Sequential Minimal Optimization (SMO). Per una trattazione approfondita delle tematiche legate a SVM si può fare riferimento a (SS02).