Il Maximum a Posteriori estimator, o maximum a posteriori probability (MAP), fornisce come stima (una delle) moda della distribuzione a posteriori.
A differenza della stima alla massima verosimiglianza, la MAP ottiene una densità a posteriori facendo uso della teoria bayesiana, unendo la conoscenza a priori
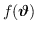 con la densità condizionale
con la densità condizionale
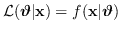 di verosimiglianza, ottenendo la nuova stima
di verosimiglianza, ottenendo la nuova stima
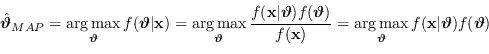 |
(2.63) |
e nel caso di eventi non correlati la formula si trasforma in
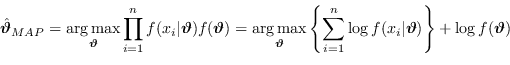 |
(2.64) |
dove, sempre per semplificare i conti, si sono sfruttate le proprietà del logaritmo.
Chiaramente se la probabilità a priori
è uniforme, MAP e MLE sono coincidenti.
Paolo medici
2025-03-12