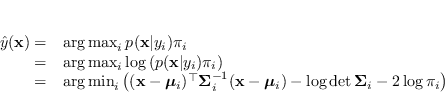Next: Naive Bayes Up: Classificatori bayesiani Previous: Il teorema di Bayes
Attraverso l'approccio bayesiano, sarebbe possibile costruire un classificatore ottimo se si conoscessero in maniera perfetta sia le probabilità a priori ![]() , sia le densità condizionate alla classe
, sia le densità condizionate alla classe ![]() .
Normalmente tali informazioni sono raramente disponibili e l'approccio adottato è quello di costruire un classificatore da un insieme di esempi (training set).
.
Normalmente tali informazioni sono raramente disponibili e l'approccio adottato è quello di costruire un classificatore da un insieme di esempi (training set).
Per modellare ![]() si utilizza normalmente un approccio parametrico e quando possibile, si fa coincidere tale distribuzione con quella di una gaussiana o con delle funzioni spline.
si utilizza normalmente un approccio parametrico e quando possibile, si fa coincidere tale distribuzione con quella di una gaussiana o con delle funzioni spline.
Le tecniche più usate per la stima sono la Maximum-Likelihood (ML) e la Stima Bayesiana che, sebbene differenti nella logica, portano a risultati quasi identici. La distribuzione gaussiana è normalmente un modello appropriato per la maggior parte dei problemi di pattern recognition.
Esaminiamo il caso abbastanza comune nel quale la probabilità delle varie classi è di tipo gaussiano multivariato di media
![]() e matrice di covarianza
e matrice di covarianza
![]() .
Il classificatore bayesiano ottimo è
.
Il classificatore bayesiano ottimo è
Paolo medici