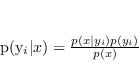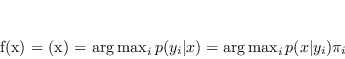Next: Il classificatore bayesiano Up: Classificatori bayesiani Previous: Classificatori bayesiani
La definizione di probabilità condizionata ci permette di ottenere immediatamente il seguente fondamentale
In questo caso
![]() con
con ![]() si avrà che:
si avrà che:
Il teorema di Bayes costituisce uno degli elementi fondamentali dell'approccio soggettivista, o personale, alle probabilità e all'inferenza statistica.
Il sistema di alternative ![]() con
con ![]() viene spesso interpretato come un insieme di cause e il teorema di Bayes, note le probabilità iniziali delle diverse cause, permette di assegnare probabilità alle cause dato un effetto
viene spesso interpretato come un insieme di cause e il teorema di Bayes, note le probabilità iniziali delle diverse cause, permette di assegnare probabilità alle cause dato un effetto ![]() .
Le probabilità
.
Le probabilità ![]() con
con ![]() possono essere interpretate come le conoscenze a priori (solitamente indicate con
possono essere interpretate come le conoscenze a priori (solitamente indicate con ![]() ), ossia quelle che si hanno prima di effettuare un esperimento statistico.
Le probabilità
), ossia quelle che si hanno prima di effettuare un esperimento statistico.
Le probabilità ![]() con
con ![]() vengono interpretate come la verosimiglianza o informazione relativa a
vengono interpretate come la verosimiglianza o informazione relativa a ![]() acquisibile eseguendo un opportuno esperimento statistico.
La formula di Bayes suggerisce dunque un meccanismo di apprendimento dall'esperienza: coniugando alcune conoscenze a priori sull'evento
acquisibile eseguendo un opportuno esperimento statistico.
La formula di Bayes suggerisce dunque un meccanismo di apprendimento dall'esperienza: coniugando alcune conoscenze a priori sull'evento ![]() date da
date da ![]() con quelle acquisibili da un esperimento statistico date da
con quelle acquisibili da un esperimento statistico date da ![]() si perviene ad una migliore conoscenza data da
si perviene ad una migliore conoscenza data da ![]() dell'evento
dell'evento ![]() detta anche probabilità a posteriori dopo aver eseguito l'esperimento.
detta anche probabilità a posteriori dopo aver eseguito l'esperimento.
Possiamo avere, per esempio, la distribuzione di probabilità per il colore delle mele, cosı come quella per le arance.
Per usare la notazione introdotta in precedenza nel teorema, chiamiamo ![]() lo stato in cui la frutta sia una mela,
lo stato in cui la frutta sia una mela, ![]() la condizione in cui la frutta sia un'arancia e sia la
la condizione in cui la frutta sia un'arancia e sia la ![]() una variabile casuale che rappresenti il colore della frutta.
Con questa notazione,
una variabile casuale che rappresenti il colore della frutta.
Con questa notazione, ![]() rappresenta la funzione densità per l'evento colore
rappresenta la funzione densità per l'evento colore ![]() subordinato al fatto che lo stato sia mela,
subordinato al fatto che lo stato sia mela, ![]() che sia arancia.
che sia arancia.
In fase di addestramento è possibile costruire la distribuzione di probabilità di ![]() per
per ![]() mela o arancia.
Oltre a questa conoscenza sono sempre note le probabilità a priori
mela o arancia.
Oltre a questa conoscenza sono sempre note le probabilità a priori ![]() e
e ![]() , che rappresentano semplicemente il numero totale di mele contro il numero di arance.
, che rappresentano semplicemente il numero totale di mele contro il numero di arance.
Quello che stiamo cercando è una formula che dica quale è la probabilità di una frutta di essere mela o un'arancia, avendo osservato un certo colore ![]() .
.
La formula di Bayes (4.7) permette proprio questo:
In generale per ![]() classi lo stimatore bayesiano si può definire come una discrimant function:
classi lo stimatore bayesiano si può definire come una discrimant function:
È anche possibile calcolare un indice, data la conoscenza a priori del problema, di quanto questo ragionamento sarà soggetto ad errori.
La probabilità di compiere un errore data una feature osservata ![]() sarà dipendente dal valore massimo delle
sarà dipendente dal valore massimo delle ![]() curve della distribuzione in
curve della distribuzione in ![]() :
:
| (4.10) |
Paolo medici