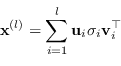Next: ZCA Up: Analisi ad autovalori Previous: Analisi ad autovalori
La Principal Component Analysis, o trasformazione discreta di Karhunen-Loeve KLT, è una tecnica che ha due importanti applicazioni nell'analisi dei dati:
Allo stesso modo esistono due formulazioni della definizione di PCA:
Un esempio pratico di riduzione delle dimensioni di un problema è l'equazione di un iperpiano in ![]() dimensioni: esiste una base dello spazio che trasforma l'equazione del piano riducendola a
dimensioni: esiste una base dello spazio che trasforma l'equazione del piano riducendola a ![]() dimensioni senza perdere informazione, facendo risparmiare così una dimensione al problema.
dimensioni senza perdere informazione, facendo risparmiare così una dimensione al problema.
Siano pertanto
![]() vettori aleatori rappresentanti i risultati di un qualche esperimento, realizzazioni di una variabile aleatoria a media nulla, che possono essere memorizzati nelle righe2.1 della matrice
vettori aleatori rappresentanti i risultati di un qualche esperimento, realizzazioni di una variabile aleatoria a media nulla, che possono essere memorizzati nelle righe2.1 della matrice ![]() di dimensioni
di dimensioni ![]() , matrice pertanto che memorizza
, matrice pertanto che memorizza ![]() vettori aleatori di dimensionalità
vettori aleatori di dimensionalità ![]() e con
e con ![]() .
Ogni riga corrisponde a un diverso risultato
.
Ogni riga corrisponde a un diverso risultato ![]() e la distribuzione di questi esperimenti deve avere media, quantomeno quella empirica, nulla.
e la distribuzione di questi esperimenti deve avere media, quantomeno quella empirica, nulla.
Assumendo che i punti abbiano media zero (cosa che si può sempre ottenere con la semplice sottrazione del centroide), la loro covarianza delle occorrenze di ![]() è data da
è data da
| (2.71) |
L'obiettivo di PCA è trovare una trasformazione ![]() ottima che trasformi i dati da correlati a decorrelati
ottima che trasformi i dati da correlati a decorrelati
| (2.72) |
Se esiste una base ortonormale ![]() , tale che la matrice di covarianza di
, tale che la matrice di covarianza di
![]() espressa con questa base sia diagonale, allora gli assi di questa nuova base si chiamano componenti principali di
espressa con questa base sia diagonale, allora gli assi di questa nuova base si chiamano componenti principali di
![]() (o della distribuzione di
(o della distribuzione di ![]() ).
Quando si ottiene una matrice di covarianza dove tutti gli elementi sono
).
Quando si ottiene una matrice di covarianza dove tutti gli elementi sono ![]() tranne che sulla diagonale, significa che sotto questa nuova base dello spazio gli eventi sono tra loro scorrelati.
tranne che sulla diagonale, significa che sotto questa nuova base dello spazio gli eventi sono tra loro scorrelati.
Questa trasformazione può essere trovata risolvendo un problema agli autovalori: si può infatti dimostrare che gli elementi della matrice di correlazione diagonale devono essere gli autovalori di ![]() e per questa ragione le varianze della proiezione del vettore
e per questa ragione le varianze della proiezione del vettore ![]() sulle componenti principali sono gli autovalori stessi:
sulle componenti principali sono gli autovalori stessi:
Per ottenere questo risultato esistono due approcci.
Siccome
![]() è una matrice simmetrica, reale, definita positiva, può essere scomposta in
è una matrice simmetrica, reale, definita positiva, può essere scomposta in
Tale tecnica tuttavia richiede il calcolo esplicito di
![]() .
Data una matrice rettangolare
.
Data una matrice rettangolare ![]() , la tecnica SVD permette esattamente di trovare gli autovalori e gli autovettori della matrice
, la tecnica SVD permette esattamente di trovare gli autovalori e gli autovettori della matrice
![]() ovvero di
ovvero di
![]() e pertanto è la tecnica più efficiente e numericamente stabile per ottenere questo risultato.
Attraverso la SVD è possibile decomporre la matrice degli eventi
e pertanto è la tecnica più efficiente e numericamente stabile per ottenere questo risultato.
Attraverso la SVD è possibile decomporre la matrice degli eventi ![]() in modo che
in modo che
| (2.75) |
Vanno ricordate le proprietà degli autovalori:
Selezionando il numero di autovettori con autovalori abbastanza grandi è possibile creare una base ortonormale ![]() dello spazio
dello spazio
![]() tale che
tale che
![]() ottenuto come proiezione
ottenuto come proiezione